
二十二
这两年,每到要写这种长文的时候,总是感觉自己越来越力不从心了。大概是接触的技术类、点评类文章越来越多、写得越多,求于外物的事情考虑得越多,反求诸己的事情反而考虑得越少。 当然也有可能是AI用得太多了,特别是GPT一类的通用语言模型爆火之后,虽然比不上手机一般成为“人工义肢”的存在,但是大模型说是工业革命一般的产物,于我而言并不夸张。至少文本上的一些dirty work,我现在几乎第一时间想到让LLM代劳,以至于硬磨半天这篇blog写什么之后,甚至问了下 ChatGPT...
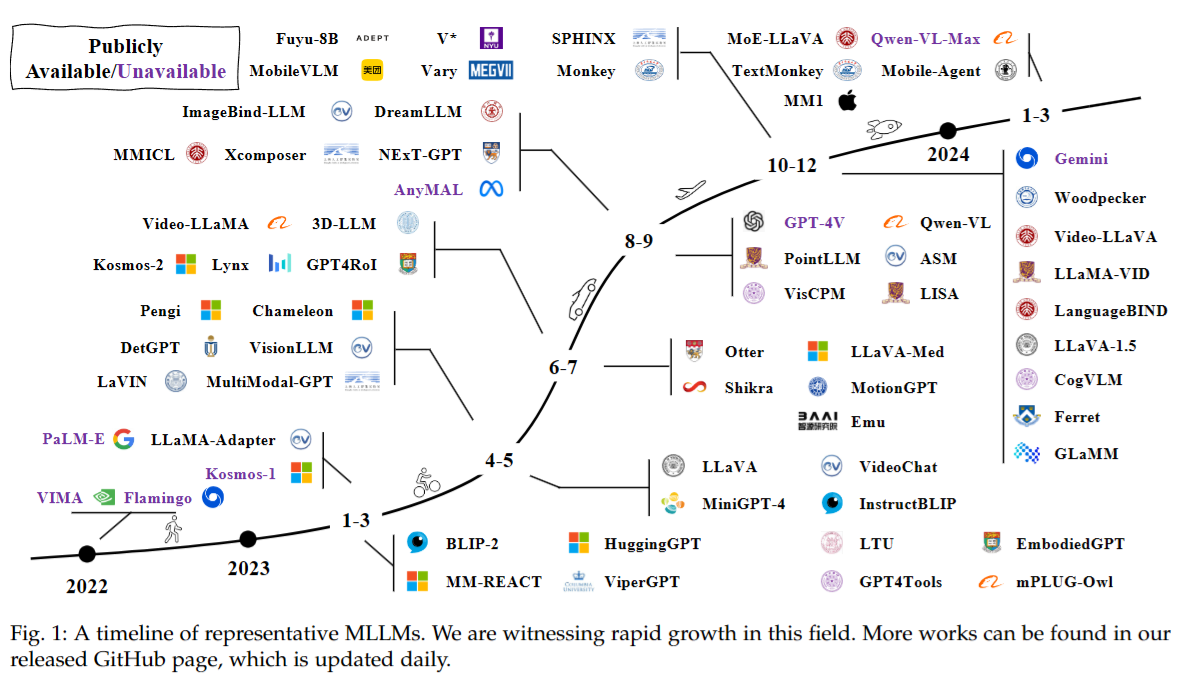
《A Survey on Multimodal Large Language Models》阅读笔记
MLLM前也有许多多模态研究,分为判别和生成两种方向。 判别的代表是OpenAI CLIP,尝试对齐图片文本对的编码,从而将视觉和文本信息投影到统一的表达空间;生成的代表是OFA,将多模态任务统一为Seq2Seq模式。 MLLM可以类比生成方向,但同时也有两个特点:1. MLLM基于Billion级别的LLM,这是先前成果所达不到的;2. MLLM使用新的训练范式来释放其能力,如多模态指令微调。这两点使得它能够拥有各种全新的能力。 现有的MLLM成果关注基于文本、图片、音频、视频输出文本的工作。更进一步的工作包括:1. 在更细的粒度上获取信息,如通过图片框或者点击物品来控制输入信息;2. 支持更多的输入输出模态;3. 更多的语言支持,如中文;4....

Hello World
把以前瞎折腾的blog推倒重做了,现在用的hexo,主题是butterfly,评论区用的DisqusJS, 在琢磨怎么上Share Buttom分享页用的AddToAny 以前的文章还没上,懒得上了Orzzz 可能回头把以前的论文笔记丢上来 就这样QWQ